JPA
JPA는 기술 명세이다
JPA는 Java Persistence API의 약자로, 자바 애플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스이다
여기서 중요하기 여겨야 할 부분은, JPA는 말 그대로 인터페이스라는 점이다. JPA는 특정 기능을 하는 라이브러리가 아니다
마치 일반적인 백엔드 API가 클라이언트가 어떻게 서버를 사용해야 하는지를 정의한 것처럼, JPA 역시 자바 애플리케이션에서 관계형 데이터베이스를 어떻게 사용해야 하는지를 정의하는 한 방법일 뿐이다
JPA는 단순히 명세서 이기 때문에 구현이 없다. JPA를 정의한 javax.persistence패키지의 대부분은 interface, enum, Exception, 그리고 각종 어노테이션으로 이루어져 있다
예를 들어, JPA의 핵심이 되는 EntityManager는 아래와 같이 javax.persistence.EntityManager라는 파일에 interface로 정의되어 있다
package javax.persistence;
import ...
public interface EntityManager {
public void persist(Object entity);
public <T> T merge(T entity);
public void remove(Object entity);
public <T> T find(Class<T> entityClass, Object primaryKey);
// More interface methods...
}
Hibernate
Hibernate는 JPA의 구현체이다
Hibernate는 JPA라는 명세의 구현체이다. 즉 위에서 언급한 javax.persistence.EntityManager와 같은 인터페이스를
직접 구현한 라이브러리이다. JPA와 Hibernate는 마치 자바의 interface와 interface를 구현한 class와 같은 관계이다

위 사진은 JPA와 Hibernate의 상속 및 구현 관계를 나타낸 것이다
JPA의 핵심인 EntityManagerFactory, EntityManager, EntityTransaction을 Hibernate에서는 각각 SessionFactory, Session, Transaction으로 상속받고 각각 Impl로 구현하고 있음을 확인할 수 있다
"Hibernate는 JPA의 구현체이다"로부터 도출되는 중요한 결론 중 하나는 JPA를 사용하기 위해서는 반드시 Hibernate를
사용할 필요가 없다는 것이다. Hibernate의 작동 방식이 마음에 들지 않는다면 언제든지 DataNucleus, EclipseLink 등
다른 JPA구현체를 사용해도 되고, 심지어 본인이 직접 JPA를 구현해서 사용할 수도 있다
다만 그렇게 하지 않는 이유는 단지 Hibernate가 굉장히 성숙한 라이브러리이기 때문이다
Spring Data JPA
Spring Data JPA는 JPA를 쓰기 편하게 만들어놓은 모듈이다
아마 대부분의 사람들은 EntityManager를 직접 다뤄본 적이 없을 것이다. DB에 접근할 필요가 있는 대부분의 상황에서
Repository를 정의하여 사용했을 것이다. 이 Repository가 바로 Spring Data JPA의 핵심이다
Spring Data JPA는 Spring에서 제공하는 모듈 중 하나로, 개발자가 JPA를 더 쉽고 편하게 사용할 수 있도록 도와준다.
이는 JPA를 한 단계 추상화시킨 Repository라는 인터페이스를 제공함으로써 이루어진다.
사용자가 Repository 인터페이스에 정해진 규칙대로 메소드를 입력하면, Spring이 알아서 해당 메소드 이름에 적합한
쿼리를 날리는 구현체를 만들어서 Bean으로 등록해 준다
Spring Data Jpa가 JPA를 추상화했다는 말은, Spring Data Jpa의 Repository의 구현에서 JPA를 사용하고 있다는 것이다
예를 들어, Repository 인터페이스의 기본 구현체인 SimpleJpaRepository의 코드를 보면 아래와 같이 내부적으로
EntityManager을 사용하고 있는 것을 볼 수 있다.
package org.springframework.data.jpa.repository.support;
import ...
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
private final EntityManager em;
public Optional<T> findById(ID id) {
Assert.notNull(id, ID_MUST_NOT_BE_NULL);
Class<T> domainType = getDomainClass();
if (metadata == null) {
return Optional.ofNullable(em.find(domainType, id));
}
LockModeType type = metadata.getLockModeType();
Map<String, Object> hints = getQueryHints().withFetchGraphs(em).asMap();
return Optional.ofNullable(type == null ? em.find(domainType, id, hints) : em.find(domainType, id, type, hints));
}
// Other methods...
}
아래 사진은 위의 내용을 요약하여 JPA, Hibernate, 그리고 Spring Data JPA의 전반적인 개념을 그림으로 표현한 것이다
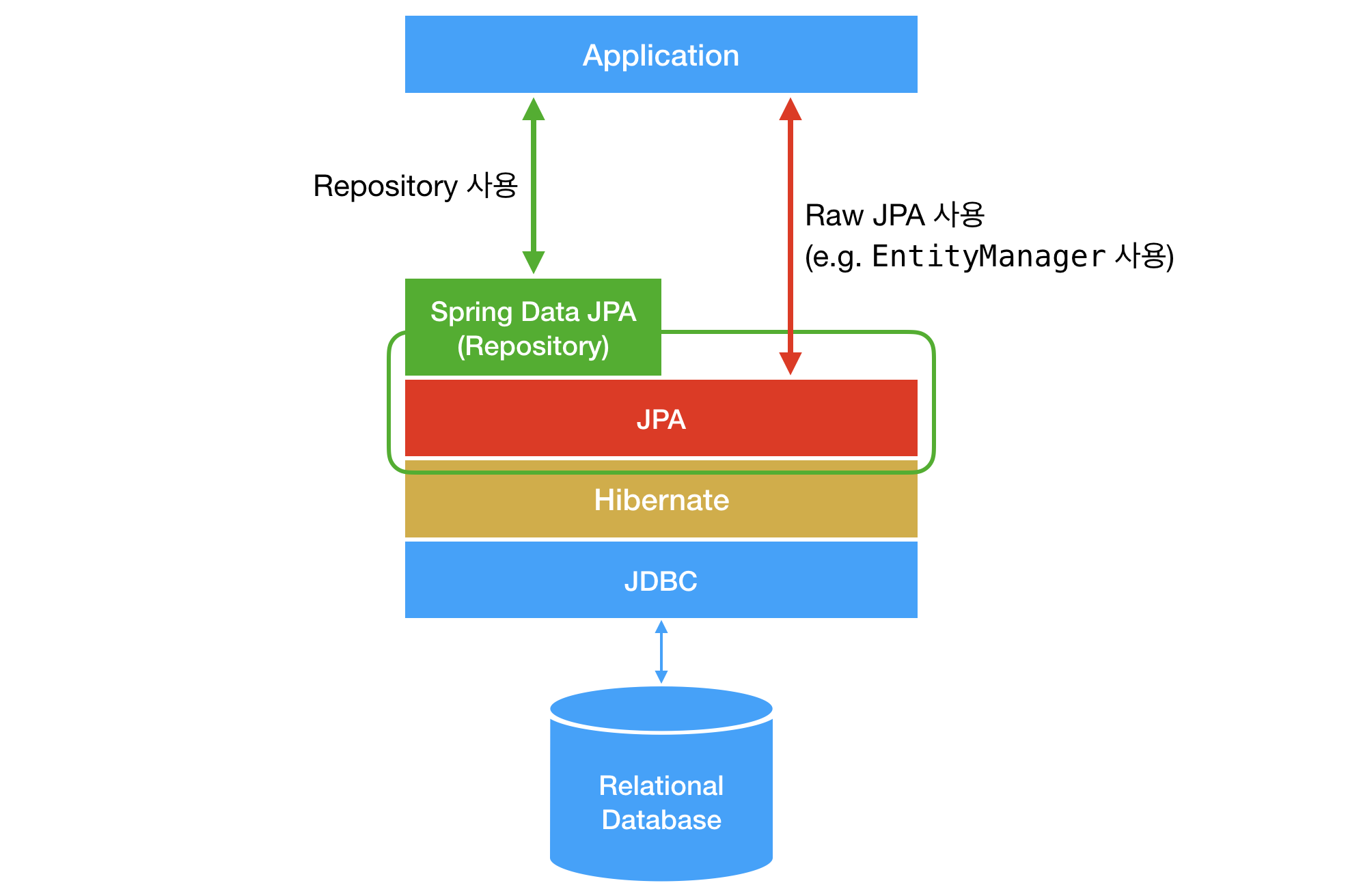
출처 https://suhwan.dev/2019/02/24/jpa-vs-hibernate-vs-spring-data-jpa/
관계도
JPA <- Hibernate <- Spring Data JPA
Hibernate를 쓰는 것과 Spring Data JPA를 쓰는 것 사이에는 큰 차이가 없다
그럼에도 스프링 진영에서는 Spring Data JPA를 개발했고, 이를 권장하고 있다
이렇게 한 단계 더 감싸 놓은 Spring Data JPA가 등장한 이유는 크게 두 가지가 있다
1. 구현체 교체의 용이성
2. 저장소 교체의 용이성
먼저 '구현체 교체의 용이성'이란
Hibernate 외에 다른 구현체로 쉽게 교체하기 위함이다
Hibernate가 언젠간 수명을 다해서 새로운 JPA 구현체가 대세로 떠오를 때, Spring Data JPA를 쓰는 중이라면 아주 쉽게 교체할 수 있다
Spring Data JPA내부에서 구현체 매핑을 지원해주기 때문이다
다음으로 '저장소 교체의 용이성' 이란
관계형 데이터베이스 외에 다른 저장소로 쉽게 교체하기 위함이다
서비스 초기에는 관계형 데이터베이스로 모든 기능을 처리했지만,
점점 트래픽이 많아져 관계형 데이터베이스로는 도저히 감당이 안 될 때가 있을 수 있다
이때 MongoDB로 교체가 필요하다면 개발자는 Spring Data JPA에서 Spring DataMongoDB로 의존성만 교체하면 된다
Spring Data의 하위 프로젝트들은 기본적인 CRUD의 인터페이스가 같기 때문이다
즉, Spring Data JPA, Spring Data Redis, Spring Data MongoDB 등등 Spring Data의 하위 프로젝트들은
save.(), findAll, findOne() 등을 인터페이스로 갖고 있다
그러다 보니 저장소가 교체되어도 기본적인 기능은 변경할 것이 없다
이러한 장점들로 인해 Hibernate를 직접 쓰기보다는 Spring Data 프로젝트를 권장하고 있다
'Spring Boot' 카테고리의 다른 글
| 스프링부트 검색, 페이징처리 하기 Pageable (0) | 2020.09.22 |
|---|---|
| 스프링부트에서 REST API 테스트코드 작성하기 (0) | 2020.09.14 |
| 게시판 게시글 정렬 하는법 (0) | 2020.09.11 |
| [스프링부트 JPA] 연관관계 매핑 (0) | 2020.09.06 |
| 자바 빌더 패턴에 대해서 + @Builder (1) | 2020.08.25 |



